
接到一个活,老板要求把这张照片,做成右边这种动画风格。
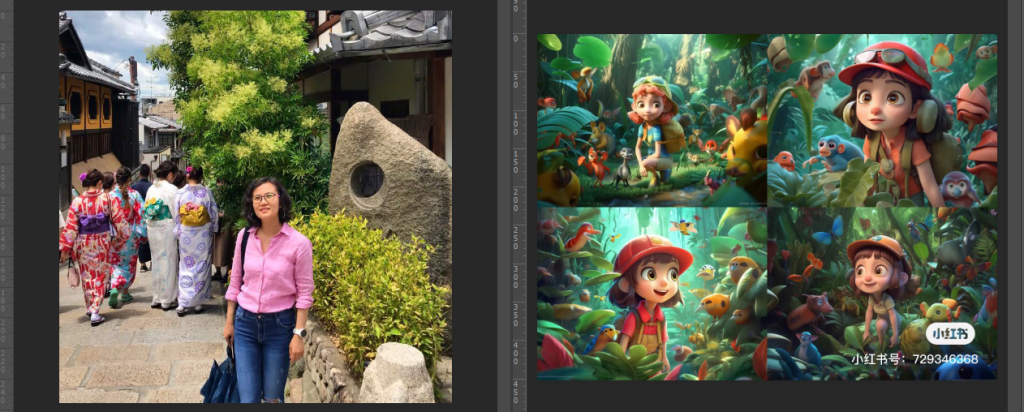
接到工作之后很兴奋。分析了一下,老板想要做出来和原图尽量接近,不能天马行空的发挥。
midjourney比较难控制,用stable diffusion更合适。
一. 初步处理
进入img2img,以图生图。打开原图后,先让SD自己识别一下图片内容,自动生成提示词。点击interrogate CLIP。
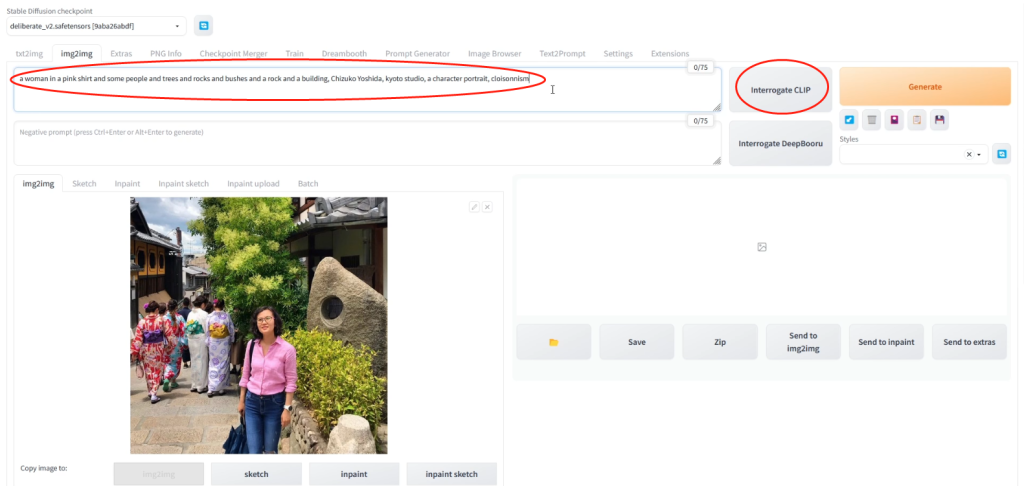
简单测试一下。在提示词前面,加上pixarstyle和cartoon两个关键字。batch size设成4,一批生成4张图。出来是这样:

人物和背景风格有点卡通的感觉了。构图我自己也算满意,但是老板要求保留原图上几个路人。所以调整一下denoising strength降噪强度。
画面上的内容,会被认为是noise噪音。denoising strength降噪强度数值越大,就会更倾向说去除噪音,由AI自己自由绘制内容。
这里尝试从0.75降到0.55,看一下效果。

现在原图左边的人物逐渐显出来了。进一步降低denoise到0.44。再和原图对比一下


现在和原图的构图已经很接近了。就选定这张作为进一步处理的基础。
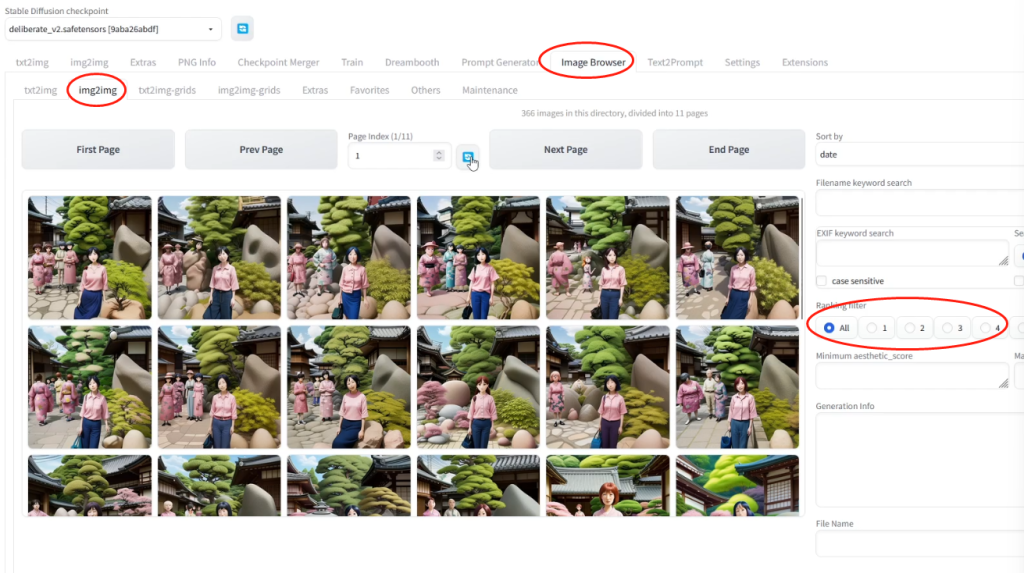
插播经验:实际出图时,反复测试会生成很多图片。建议安装extension 扩展程序:Image browser 图片浏览器。在这里,可以随时给比较满意的图片打个评分。便于后续挑选整理。
二. Inpaint,脸部局部重绘
选send to inpaint。下面准备保留画面其他内容,只重绘人物脸部。
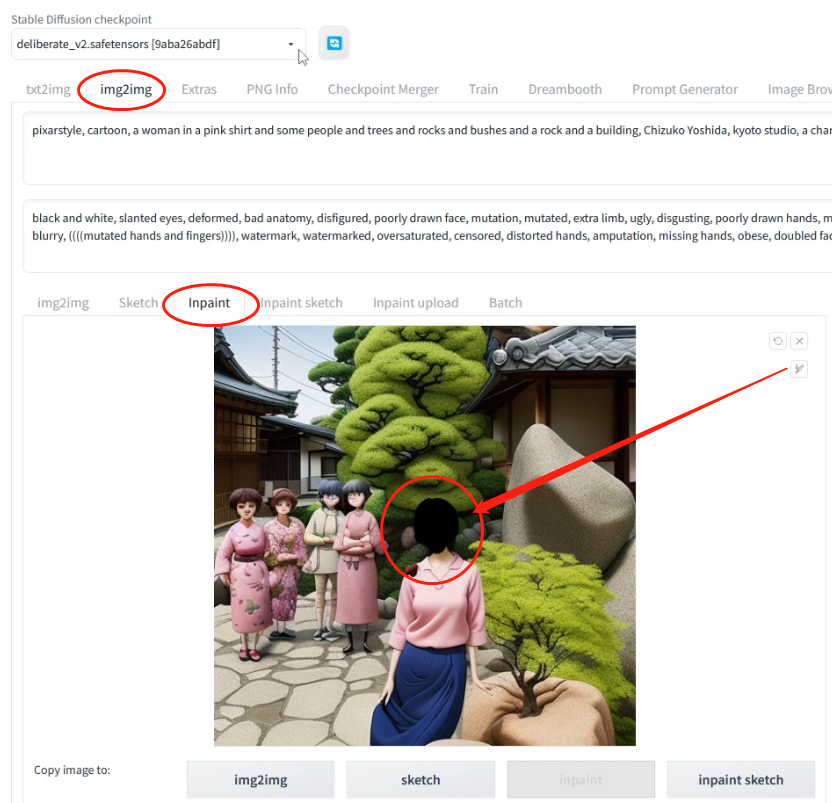
在图中,把需要AI重画的人物脸部区域标注出来。
Mask mode 蒙版模式:inpaint masked。重绘标注区域。
Masked content 蒙版内容: original,原始内容。
Inpaint area 重绘区域:only masked,仅蒙版区域。
Restore faces重建人脸:选中。
按老板要求,想要pixar效果。鉴于pixar是好莱坞著名工作室,出过很多动画片,我们优先到https://civitai.com/ 去搜索一下有没有人用pixar动画片训练过专门的模型。
图然不出所料。看起来这个模型效果不错。
留意介绍中:trigger words 触发关键字是:pixarstyle。
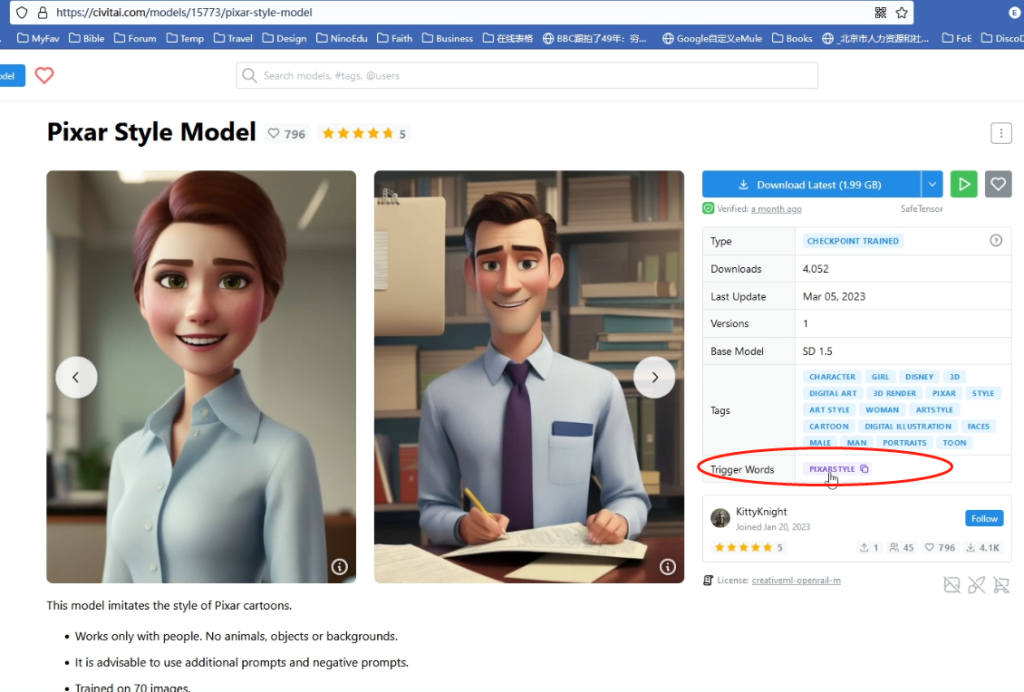
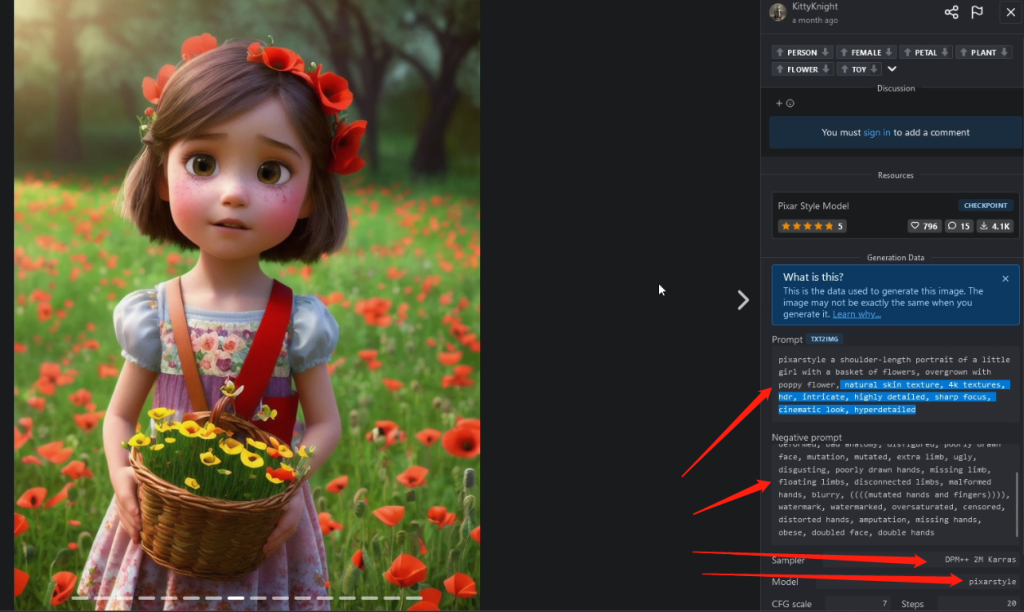
再点击几个比较好的案例,看一下详细的关键字和negative prompt负面关键字。直接copy过来之后,建议看一下,不要无脑复制。可能会有多余的关键字。
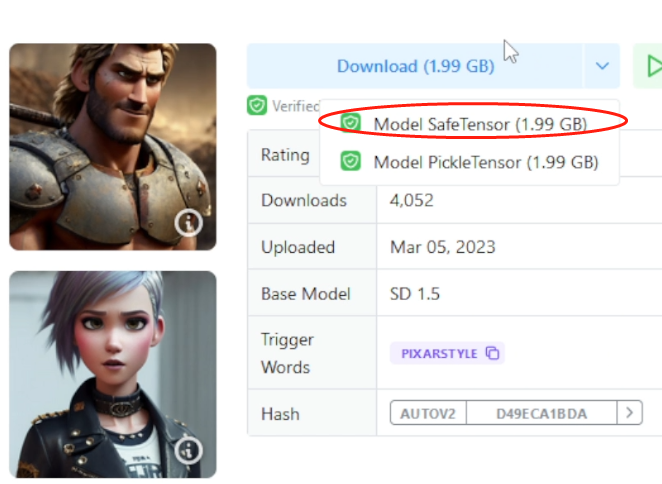
之后,到下载页,下载SafeTensor格式。如果有这个格式可用,尽量用这个。避免ckpt里可能会有恶意代码。
下载好的文件,放在/models/Stable-diffusion/目录下。
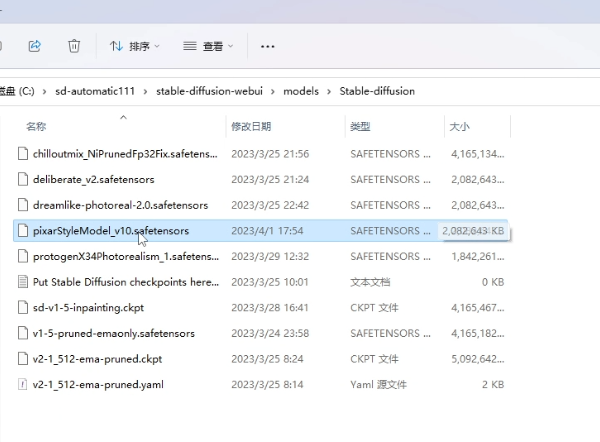
之后回到webui,刷新列表后,选择新下载的pixarStyleModel。
粘贴关键字。sampler按示例,选DPM++ 2S a Karras。
其他参数不变,看一下效果。

是不是有点pixar的感觉了?但是不够明显
继续调整
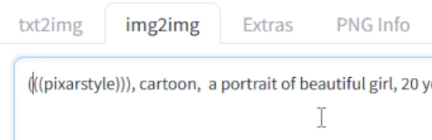
第一,增加提示词里,pixarstyle权重。见下图。
每加一层括号,等于权重 * 1.1。3层括号 = *1.1*1.1*1.1 = 1.331。权重上升30%
第二,增加CFG Scale权重。这是整体提示词,对画面影响的权重,一般在6-11之间。
看,这样pixar风格就明显多了。

后面仍然用inpaint整理肩膀上的辫子。然后再用同样办法,逐个修复后面4人的表情。
第一稿出图是这样,对比原图:


三. 发生意外
做好之后,老板表示之所以选这张照片,主要是看上了后面4个人的和服。
理工男遭到10000点暴击。很难理解,如果喜欢和服,前面站的那个人是干嘛的?
唉。。。从头再来
一稿pixar风,交老板

另外一稿,是我自己比较喜欢的,我宁可把后那四个人,改成一块大石头!!!😡😡😡

知识点
💡 – interrogate CLIP 可以在img2img里,先自动获取原图的关键字描述 – Inpaint,可以在画面中标记位置,局部重绘,替换画面内容 – 模型下载资源,SD玩家必备 https://civitai.com/
配置")

